Exploiting label invariance in unlabeled data
Semi-supervised learning tries to combine supervised and unsupervised learning, leveraging unlabeled data to simplify training even when scarce labeled data is available. It has a pretty long history1, but it never really worked. In recent years it gained renewed interest (along with self-supervised learning) after the deep learning revolution. New methods differ from older one, and typically rely on different flavors of:
- self-training / pseudolabeling (teacher-student)
- consistency regularization
- aggressive data augmentations
See UDA, MixMatch, FixMatch, Meta Pseudo Labels in the last 2-3 years.
The underlying assumption of most semi-supervised learning work are minimal: pretty much nothing is known about unlabeled examples, other than their having the same distribution of the labeled data.. But.. is that realistic? In the real-world, we often we know a lot about the problem at hand! That’s why we can (and should!) often CHEAT a little bit.
A pragmatic perspective 💡
Suprisingly often, we can find “target-consistent” groups in our unlabeled data, where the label is consistent, although unknown. Similar ideas have also been exploited for self-supervised learning approaches (e.g., Time-Contrastive Networks, Geography-Aware Self-supervised Learning).
A few practical examples are:
- different point of views of the same scene
- spatially aligned satellite images over time
- different images from the same device



So here is a simple idea that I called “Domain-aware Semi-supervised learning” (DSSL). Let’s use domain knowledge to identify groups of unlabeled data that are target-consistent. Then, for each batch, we take $N$ labeled examples and $M$ target-consistent groups of unlabeled examples and compute a loss as:
\[\mathcal{L} = \mathcal{L}_s + \lambda_u\mathcal{L}_u\]where we sum the standard supervised loss with a domain-aware unsupervised loss term (consistency term) computed, for each group $G^j$, as in the following figure:
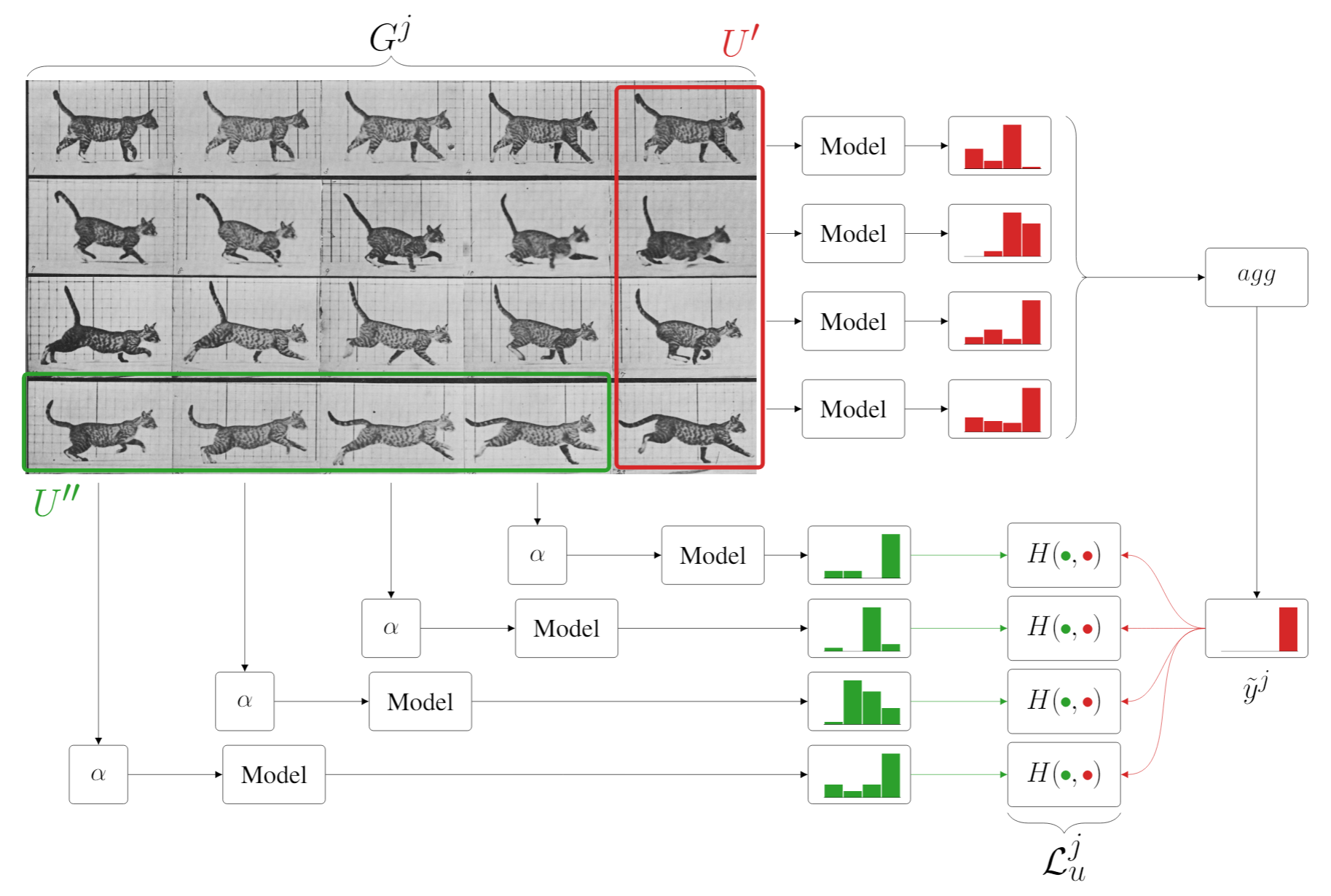
In summary, we want model predictions to be consistent across each group. To do so:
- we aggregate multiple non-augmented predictions $U’$ obtaining a higher-quality pseudo-label;
- we use multiple (augmented) items $U’’$ to compute the consistency loss exploiting the natural augmentations provided by the underlying domain.
Let’s see 3 real-world cases where I applied this simple technique to get a big performance improvement.
Weather classification
Consider the task of classifying weather in road scenes. We have a few hundreds labeled images, and thousands of unlabeled short videos from the BDD100k dataset.
We know that weather doesn’t change instantaneously: frames from the same video are “target-consistent” (left: sunny; right: rainy).


DSSL can easily be applied here: we compute a pseudolabel as the average prediction of the current model on multiple frames of the same (unlabeled) video.
This works great compared to just training in a supervised way on the available data. I also compared DSSL with a semi-supervised baseline (essentially, FixMatch with no bells and whistles), showing that DSSL outperforms that, too.
Ego-vehicle segmentation in the wild
A task that comes up surprisingly often in practical computer vision on road scenes is the segmentation of the ego-vehicle, in videos where the camera pose, vehicle type, etc. are all unknown.




For each vehicle, we do know that the camera position doesn’t change over time: images from the same device are “target-consistent”.
Having access to millions of unlabeled images from a private dataset, DSSL can easily be applied: a pseudo-label (or pseudo-mask) can be obtained averaging the predicted segmentation masks over multiple images from the same camera. This gives you on average more than a +5 IoU improvements “for free” over both supervised and semi-supervised learning baselines.
Vehicle identification from sensor data
Finally, another practical tasks. Assume we have access to streams of IMU + GPS data from connected vehicles, and we want to know what kind of vehicle generated the data. For a subset of vehicles, we might know make + model. Interestingly, in this case it’s not even possible to manually label more data - unless you know somebody that can interpret IMU data!
But also in this case we know valuable information: given a vehicle, its type doesn’t change (duh!). So, data collected from the same device over time are “target-consistent”.
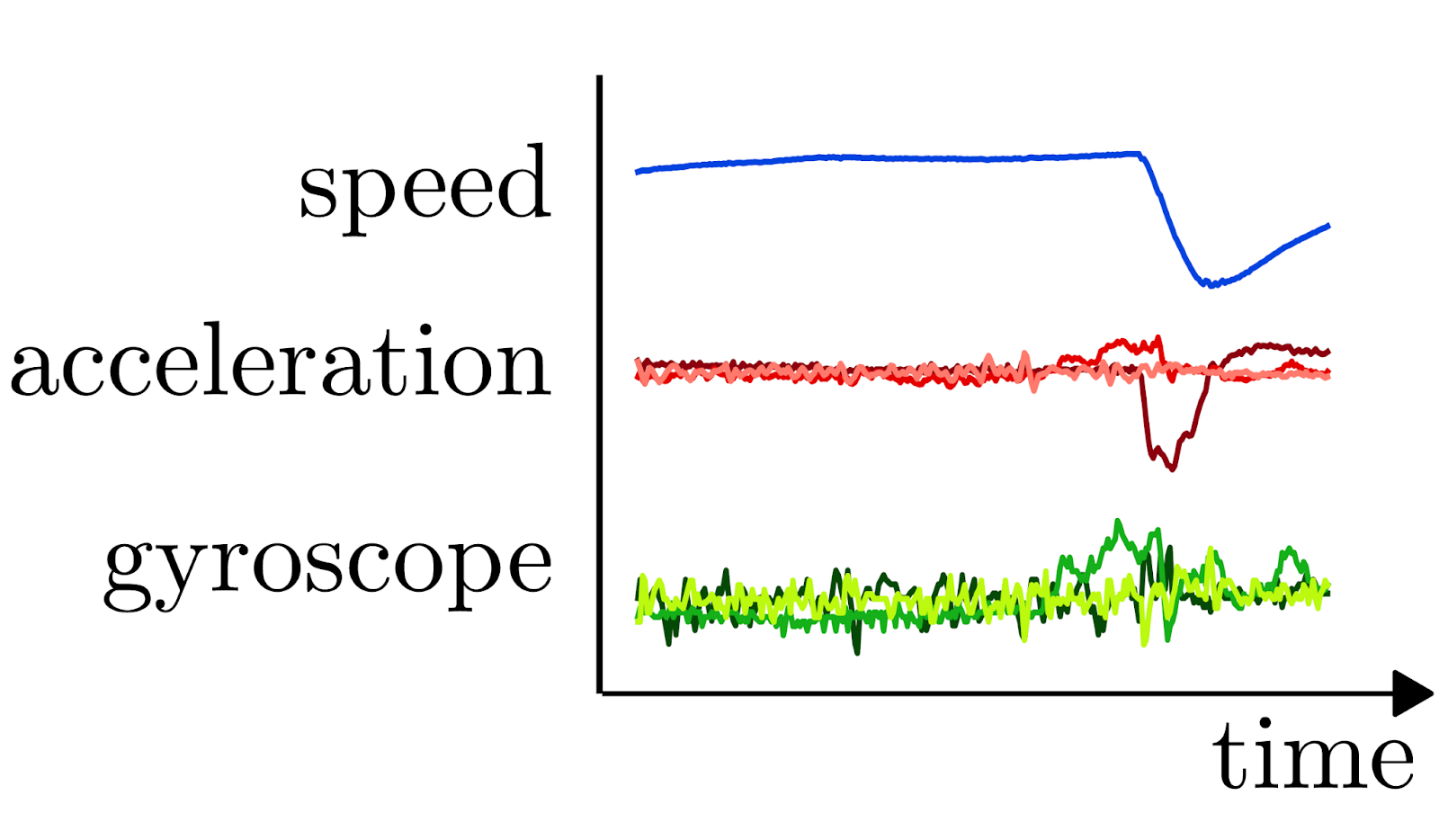
DSSL works well also in this case. Additional bonus: this is a somewhat less standard task - there’s no standard recipe for data augmentations on IMU+GPS, and most self- or semi-supervised methods are designed and tuned for image-related tasks. Indeed, I couldn’t get the Fixmatch baseline to work at all for this problem, even throwing at it all the IMU+GPS augmentations I had. While DSSL just worked out of the box.
Conclusions
I briefly showed here a simple yet effective method to exploit domain knowledge in a semi-supervised framework. Some more details can be found in the paper that I presented at a ICCV workshop this year.
The main takeaway should be: if you can cheat and exploit some knowledge of your problem or the process that generates your data, by all means do!
-
Olivier Chapelle, B Scholkopf, and A Zien. “Semi-Supervised Learning”. MIT Press, 2006 ↩